
# 1. Q-Learning
강화학습(Reinforcement Learning) - 1.Value Function
# 1. 강화학습이란? 강화학습이란 어떤 Enviroment을 탐색하는 Agent가 현재의 State을 인식하여 어떤 Action을 취하면 그 행동에 대한 Reward가 주어지게 되고, Reward를 최대화하는 Action을 찾는 Policy를 찾
repoji-dataengineer.tistory.com
여기서 Q-Value Function까지 살펴보았다.
이제 모든 {State,Action} Pair에 해당하는 Q-value를 구하고 최대값을 찾는 게 Q-Learning이다.
그렇다면, 현재까지 알고 있는 식을 활용하여 다음과 같은 단계를 거치게 된다.
모든 Q(s, a)를 0으로 초기화 한다.
이 후, 다음 동작들을 반복한다.
- Q(s, a)에 따라 동작을 실행한다.
- 행동에 따른 보상을 받는다.
- 새로운 상태를 확인한다.
- Q(s, a) = reward + Max Q(s', a')을 활용하여 Q(s,a)를 업데이트 한다
Discounted Reward
하지만, 이렇게 되면 같은 Q(s,a)가 많아지는 단점이 있다. 따라서, Discounted Reward값을 곱해서 같은 Q(s,a)가 나올 확률을 줄여준다.
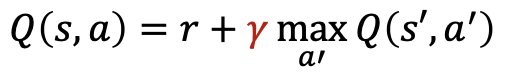
ε-탐욕 정책(ε-greedy Policy)
이렇게 해도 새로운 탐색(Exploration)이 이루어지지는 않는다는 단점이 있다. 그래서 ε-탐욕 정책(ε-greedy Policy)을 활용하여 새로운 것에 대한 탐색을 늘리도록 한다.

따라서, 1-epsilon의 확률로는 Q(s,a)를 따르고, epsilon의 확률로는 Random하게 진행되도록 한다. 하지만, 이게 초반에는 많은 탐색이 필요하지만, 갈수록 탐색(Exploration)보다는 정답에 가까워지는 Exploitation이 더 많아져야 하므로 ε decaying을 통해서 탐색 시도를 줄일 수 있다.
Temporal Difference
Temporal Difference, 시간차 제어라고 부르며, Episode 별이 아닌 Timestamp별로 업데이트 하는 방식을 말한다.

여기까지 하면, 전체적인 알고리즘 과정이 다음과 같다.

'🗂️Data Science > Aritificial Intelli' 카테고리의 다른 글
| 강화학습(Reinforcement Learning) - 3.DQN (0) | 2022.12.07 |
|---|---|
| 강화학습(Reinforcement Learning) - 1.Value Function (0) | 2022.12.07 |
| Pattern mining (0) | 2022.11.26 |
| 주성분분석(Principal Component Analysis) (0) | 2022.11.22 |